Introduction
Github recently introduced its new and improved search feature. While the improvements make search for content much easier, it has certainly introduced its share of problems as well. This is just another example.
Searching Github Manually
When I first acquired a Google API key, I quickly noticed that many (if not all) keys start with the same 4+ characters: "AIza". These keys can give access to any API services the owner of the key has activated. While they are not incredibly secret (I have seen many used in Javascript for the Maps API), and it's easy to replace them, they still aren't things the owners would likely want to be harvested. When the new Github search was introduced and the related private files started to be found, I decided to see if any developers had - intentionally or accidentally - left them in their code.
When we first visit the search page and look for "AIza", we are presented with the following:

Nice - over 14,000 results. While we can immediately start thinking about ways to automate the process of harvesting these, we quickly run into an issue: Github only allows us to search 99 pages, each with 10 results. This only allows us to get less than 1,000 results.
While I haven't yet found a way to obtain all the results (comment below if you know of a way - I'd love to hear it!), my current solution to this is as follows:
- Github allows us to sort by both "Best Match" and "Last Indexed". I've found that for a large number of results, they produce different output.
- We can search through the overall results (all 99 pages) using both of these sorting methods. Then, we can also search using individual languages (notice them on the left side of the image). By searching these, we get a maximum of 99 pages for each language, and we can use both sorting methods again.
With this being the case, we can now surpass our limit of under 1,000 results. While we still can't always get every result, let's automate the harvesting process we have so far and see what we find.
Automating the Search
For automating this search, we'll employ a few basic web scraping techniques, and the following fantastic Python modules:
- BeautifulSoup4 for HTML parsing (This post is using the default BeautifulSoup HTML parser. If you have lxml installed (recommended), BeautifulSoup will use it by default)
- Requests for making our, well, requests to Github
- re for regex matching
For the sake of this post, I'll step through the methodology used to harvest information like this. First, we can use requests to get the source of a webpage as follows:
Now that we have the raw source, we can create a BeautifulSoup object with it:
Now that we have an easily parseable object, what should we look for? Let's try to find a unique attribute about the results that would allow us to quickly search for it an find the text we're looking for. I usually do this by right-clicking the text in question, clicking "Inspect Element" (this is Chrome), and then seeing what kind of HTML element it is embedded in. Doing this, we see the following:

We can see here that the result text is within a 'div' with a class of 'line', so it's a safe bet to try and extract all elements that match this criteria.
In general, creating a BeautifulSoup object gives us the ability to quickly parse out a list of specific HTML elements we want using the syntax soup.find_all(element_tag, { attribute : value }). However, since searching for an element by class is such a common need, BeautifulSoup makes it easier for us by letting us search with the syntax soup.find_all(element_tag, class_name). Let's extract these values:
Great, making progress! The next thing we want to do is extract just the raw text from these results. BeautifulSoup makes it really easy for us to do this by allowing us to call result.text for each result in our list. Let's give that a shot.
The last thing we need to do is create a regex to find the matches. Since we know each expression begins with "AIza" and can see that they are each 39 characters long, the following expression should serve our purposes nicely:
Just like that, we have our keys. The last thing we need to do to make our script a bit more efficient is to get the number of pages for each language. We could do this two ways:

Now that we have the general idea as well as the data we need, here's the entire script, which checks for duplicates, runs through all iterations listed in the beginning of this post, and writes the results to 'google_keys.txt'.
Since it looks like (at the time of this writing) I'm running into issues having Github return results for each specific language (no matter the search query), here is a small subset of the results found (approx. 1,000 out of 4,086 enumerated keys) when developing the tool: http://pastebin.com/XEe1WuvG. Of course, some authors have intentionally added obfuscation to their keys (such as replacing characters with 'XXXX', etc.), however this should be a reminder to always sanitize data before publishing it to a public repository!
As always, let me know if you have any questions!
-Jordan
Now that we have an easily parseable object, what should we look for? Let's try to find a unique attribute about the results that would allow us to quickly search for it an find the text we're looking for. I usually do this by right-clicking the text in question, clicking "Inspect Element" (this is Chrome), and then seeing what kind of HTML element it is embedded in. Doing this, we see the following:
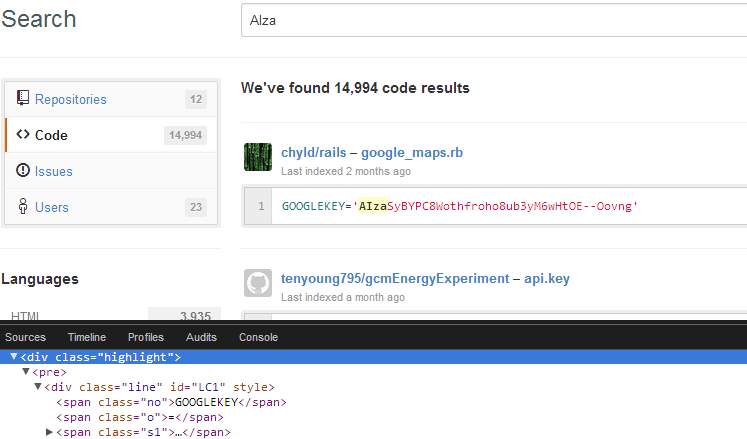
We can see here that the result text is within a 'div' with a class of 'line', so it's a safe bet to try and extract all elements that match this criteria.
In general, creating a BeautifulSoup object gives us the ability to quickly parse out a list of specific HTML elements we want using the syntax soup.find_all(element_tag, { attribute : value }). However, since searching for an element by class is such a common need, BeautifulSoup makes it easier for us by letting us search with the syntax soup.find_all(element_tag, class_name). Let's extract these values:
Great, making progress! The next thing we want to do is extract just the raw text from these results. BeautifulSoup makes it really easy for us to do this by allowing us to call result.text for each result in our list. Let's give that a shot.
The last thing we need to do is create a regex to find the matches. Since we know each expression begins with "AIza" and can see that they are each 39 characters long, the following expression should serve our purposes nicely:
Just like that, we have our keys. The last thing we need to do to make our script a bit more efficient is to get the number of pages for each language. We could do this two ways:
- Navigating to each language page and getting the maximum number of pages
- From our starting page, pull the number of results for each language and divide by 10
Since it will result in less requests if we go the second route, let's pursue that option. From our page, we can see the following HTML structure of the side panel:

So it looks like want both the URL to use, and the text from the "span" tag with the "count" class. We can easily retrieve both of these with BeautifulSoup:
Now that we have the general idea as well as the data we need, here's the entire script, which checks for duplicates, runs through all iterations listed in the beginning of this post, and writes the results to 'google_keys.txt'.
Since it looks like (at the time of this writing) I'm running into issues having Github return results for each specific language (no matter the search query), here is a small subset of the results found (approx. 1,000 out of 4,086 enumerated keys) when developing the tool: http://pastebin.com/XEe1WuvG. Of course, some authors have intentionally added obfuscation to their keys (such as replacing characters with 'XXXX', etc.), however this should be a reminder to always sanitize data before publishing it to a public repository!
As always, let me know if you have any questions!
-Jordan
Just do a search for "AIzaa", then for "AIzab", then "AIzac", etc...
ReplyDeletethanks but ,how to get the cx?
ReplyDeleteSo apparently you can get around the search limit of 1000 by breaking the query into chunks of certain time frames using the sort on created feature. I haven't tried it yet.
ReplyDelete